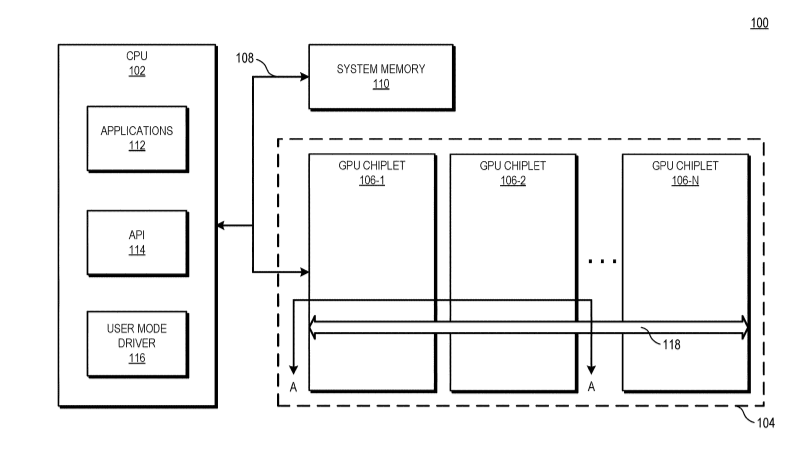
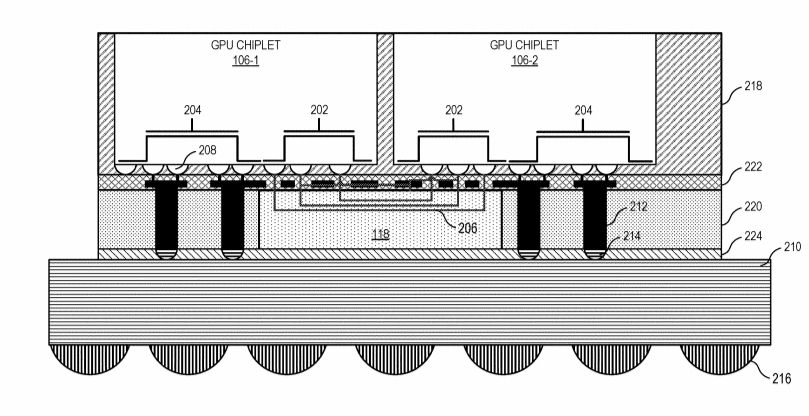
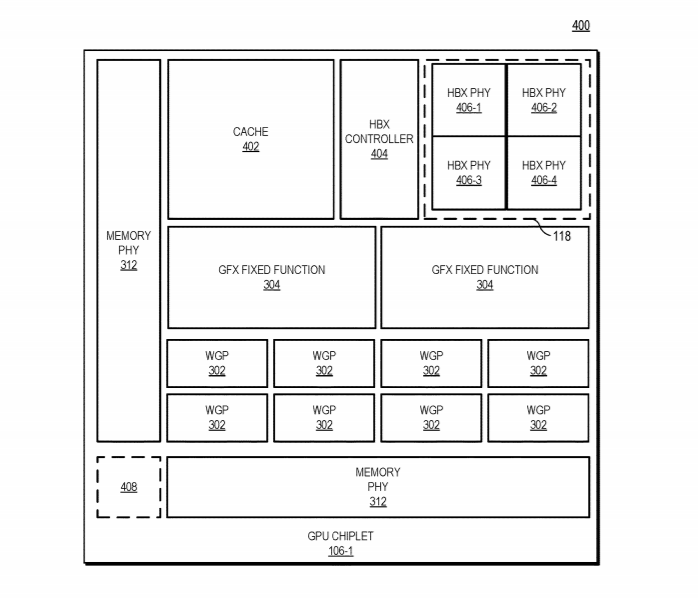
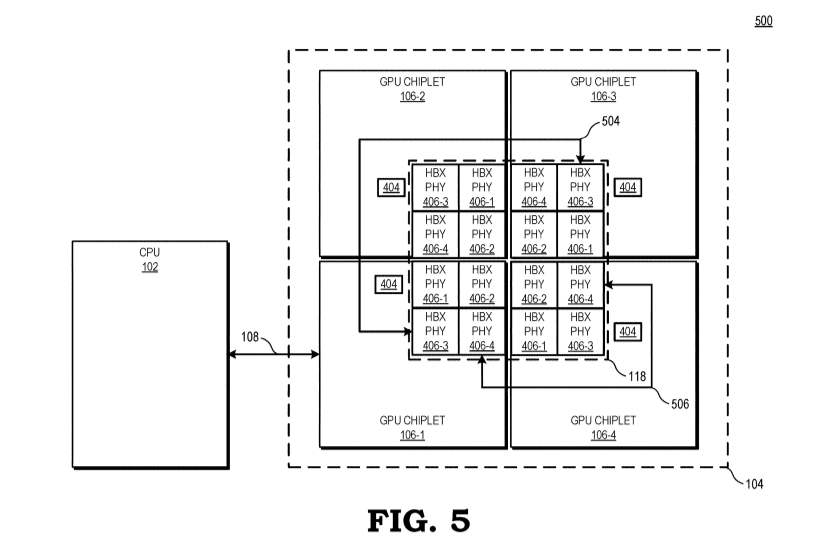
Bom, os dies destas MI100 já são não propriamente pequenos, e não havendo redução de processo de fabrico, e sendo que os benefícios da "reduçaõ" cada vez menores, a única forma de escalar será essa.
Mas falta saber em concreto que tipo de solução será usado.
A AMD e os vários parceiros (quer TSMC, quer as empresas de "packaging" como a ASE, AMKOR e SPIL) têm as suas soluções a que se podem vir a acrescentar agora as da Xilinx que já usava ainda antes da AMD.
O suspeito do costume já publicou 2 de 3 séries de patentes da Xilinx, uma boa parte deles refere-se precisamente a multi chip/die stacking.
Here is Xilinx's long-awaited list of patents, highlighting the latest developments that may be interesting for future AMD projects. (1/3)
https://twitter.com/Underfox3/status/1330512321970659329
Here is Xilinx's long-awaited list of patents, highlighting the latest developments that may be interesting for future AMD projects. (2/3)
https://twitter.com/Underfox3/status/1332872721085165571
Mas falta saber em concreto que tipo de solução será usado.
A AMD e os vários parceiros (quer TSMC, quer as empresas de "packaging" como a ASE, AMKOR e SPIL) têm as suas soluções a que se podem vir a acrescentar agora as da Xilinx que já usava ainda antes da AMD.
O suspeito do costume já publicou 2 de 3 séries de patentes da Xilinx, uma boa parte deles refere-se precisamente a multi chip/die stacking.
Here is Xilinx's long-awaited list of patents, highlighting the latest developments that may be interesting for future AMD projects. (1/3)
https://twitter.com/Underfox3/status/1330512321970659329
Here is Xilinx's long-awaited list of patents, highlighting the latest developments that may be interesting for future AMD projects. (2/3)
https://twitter.com/Underfox3/status/1332872721085165571