
Nemesis11
Power Member
Isto já é algo antigo, mas aqui fica. É apenas um Business Card Computer que corre Linux.



As Specs é um Allwinner F1C100s (ARM9 + 32 MB RAM) e 8 MB Flash.
Custos em 2019:
https://www.thirtythreeforty.net/posts/2019/12/my-business-card-runs-linux/
https://www.thirtythreeforty.net/posts/2019/12/designing-my-linux-business-card/
As Specs é um Allwinner F1C100s (ARM9 + 32 MB RAM) e 8 MB Flash.
Custos em 2019:
| Component | Price |
|---|---|
| F1C100s | $1.42 |
| PCB | $0.80 |
| 8MB flash | $0.17 |
| All other components | $0.49 |
| Total | $2.88 |
https://www.thirtythreeforty.net/posts/2019/12/my-business-card-runs-linux/
https://www.thirtythreeforty.net/posts/2019/12/designing-my-linux-business-card/
")



 madness!
madness!








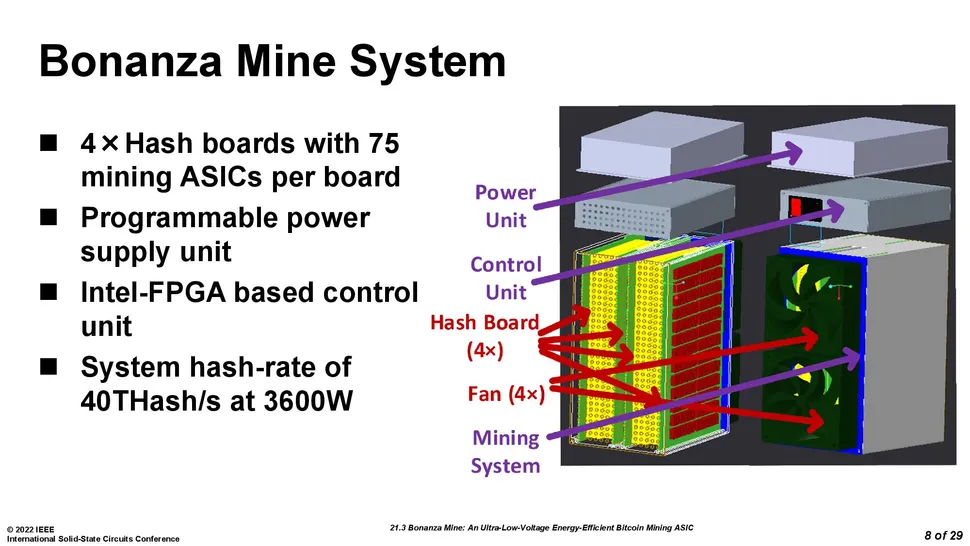




















 )
)


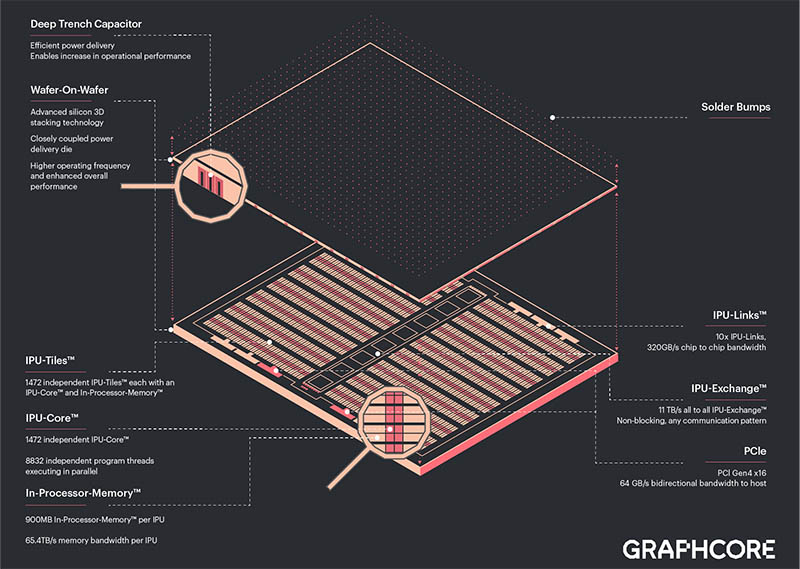








 cada um usa o que tem mais à mão, penso eu de que
cada um usa o que tem mais à mão, penso eu de que 






