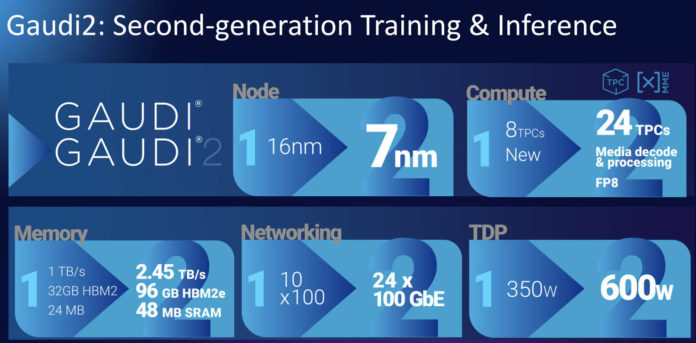
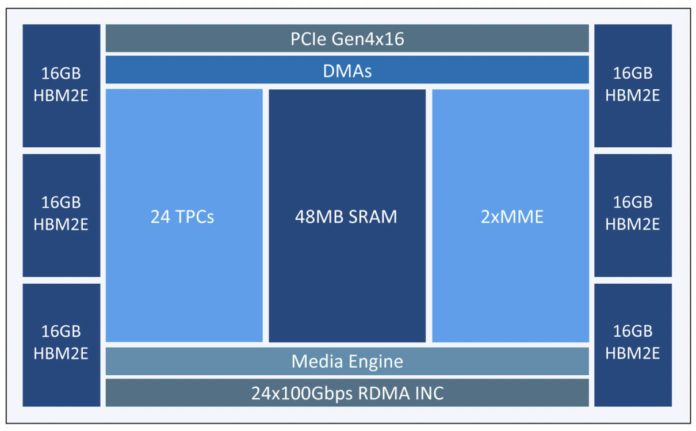
Nemesis11
Power Member
O SOC da 2ª Board parece ser o mais interessante. Ele tem a marcação "VIA John":

Este "VIA John", parece que era a 3ª Geração dos "Via Corefusion". SOCs x86 muito integrados, low power. Entretanto, parece que foi cancelado:
Foto do "VIA Mark" (1ª geração):


Foto do "VIA Luke" (2ª geração):



Este "VIA John", parece que era a 3ª Geração dos "Via Corefusion". SOCs x86 muito integrados, low power. Entretanto, parece que foi cancelado:
https://en.wikipedia.org/wiki/VIA_CoreFusion#JohnLittle is known about the Corefusion John, other than a VIA roadmap PDF from 2005 found here. It was apparently planned as a successor to the Luke, and supposed planned features were to include DDR2 support, hardware WMV9 decoding and HD audio support. It is unknown if this part was ever released, but it likely would have used some variant of a VIA C7 core (since VIA lost licenses required to produce the C3 series.)
Foto do "VIA Mark" (1ª geração):
Foto do "VIA Luke" (2ª geração):










")