Aparentemente durante o Intel Architecture Day não se falou apenas de hardware, e só há pouco é que me apercebi do reboliço de uma notícia do Phoronix...
mas tirando um outro artigo do Phoronix da altura
Intel Developing "oneAPI" For Optimized Code Across CPUs, GPUs, FPGAs & More
não encontrei muito mais
Intel One API to Rule Them All Is Much Needed


https://www.servethehome.com/intel-one-api-to-rule-them-all-is-much-needed/
De repente tive um flashback
Nota: não assisti ao Intel Architecture Day, estava de férias por isso passou-me ao lado.
por isso passou-me ao lado.
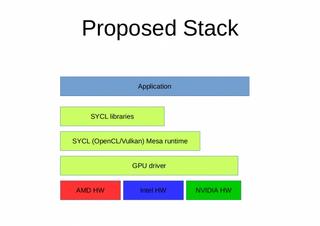
https://www.phoronix.com/scan.php?page=news_item&px=Intel-SYCL-For-LLVM-Clang"We (Intel) would like to request to add SYCL programming model support to LLVM/Clang project to facilitate collaboration on C++ single-source heterogeneous programming for accelerators like GPU, FPGA, DSP, etc. from different hardware and software vendors."
mas tirando um outro artigo do Phoronix da altura
Intel Developing "oneAPI" For Optimized Code Across CPUs, GPUs, FPGAs & More
não encontrei muito mais
Intel One API to Rule Them All Is Much Needed
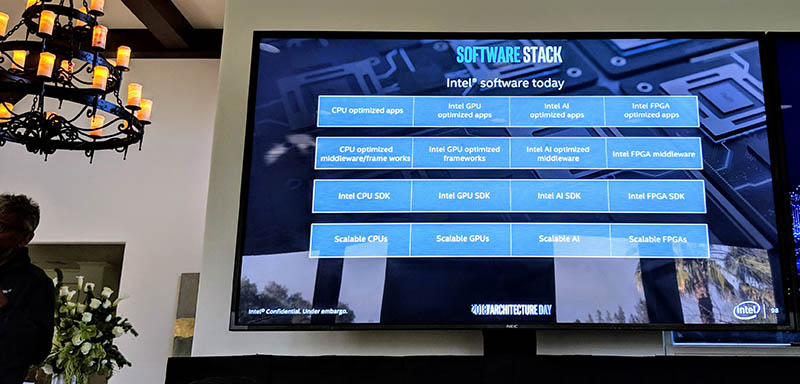
A key tenant in the One API solution is unifying all of the hardware, SDKs, and middleware used to deliver optimized software experiences to users of Intel hardware, whether that is x86 CPUs, AI accelerators, GPUs, or FPGAs.
The reason Intel is going the route of using a common API across products is that the company’s complexity would soon get out of hand. It already works on everything from drivers, to libraries and middleware, to application optimization throughout a number of product lines and categories. Instead of having to maintain very different APIs for different hardware, it can focus on developing software with a common API, and hiding hardware complexity at the back end.
https://www.servethehome.com/intel-one-api-to-rule-them-all-is-much-needed/
De repente tive um flashback
Nota: não assisti ao Intel Architecture Day, estava de férias
por isso passou-me ao lado.