@PipocaGorda Mas é mais que óbvio que vão ser 70% ou mais, em Ray Tracing  .
.
..@PipocaGorda Mas é mais que óbvio que vão ser 70% ou mais, em Ray Tracing
Se o que estava no lugares dos * for leak, então esquece. A fiabilidade desse site é muito perto de 0.
")
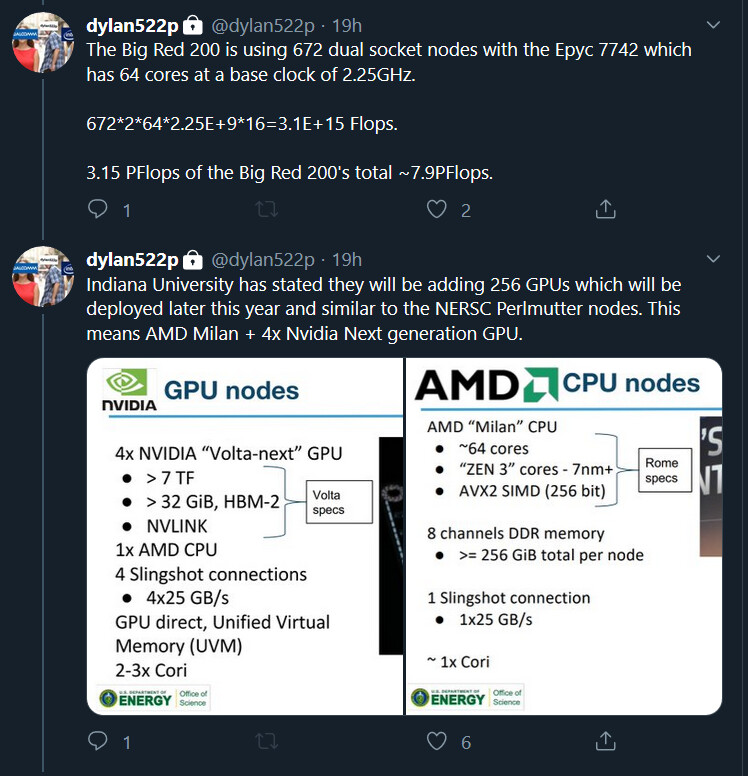
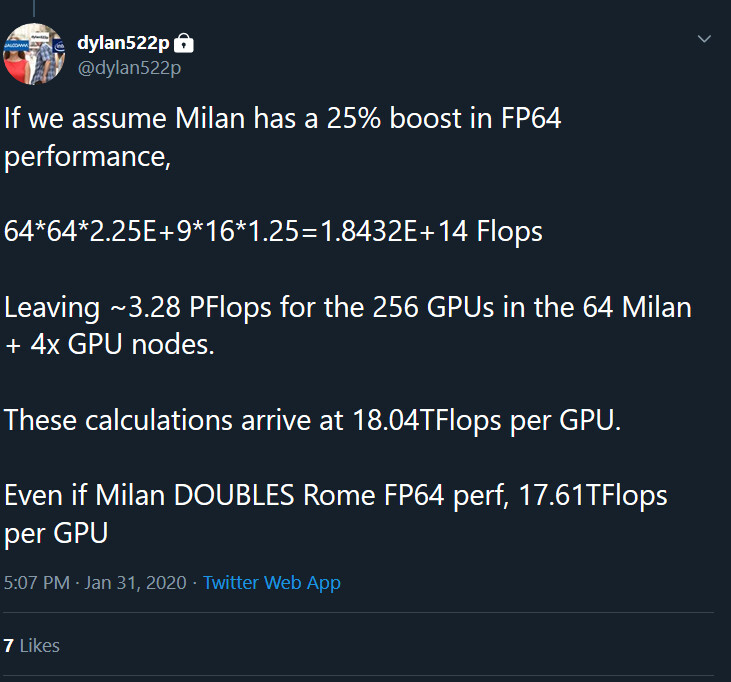
Já estive a investigar noutras fontes. Os supercomputadores Big Red da Nvidia são 75% mais rápidos com os novos Ampere ao invés com Turing.


Não me parece nada de outro mundo.
A 2080 Ti faz 13,5 TFlops. Uma 3080 Ti vem de certeza com mais Cuda Cores e com clock mais elevado, o que faz aumentar os TF.
- INT32 Unit remains unchanged.
- Double the FP32 Unit for shader proportion.
- The performance of the new Tensor Core is doubled.
- Enhanced L1 Data Cache for more comprehensive functions.
- True architecture for RTX GAMING with all-new design RT CORE ADVANCED.
Andam ai uns leaks que o GA100 terá um die size massivo de 826mm2... A 3080 Ti será GA103 e a 3080 será GA104. por isso esse GA100 presumo que seja uma Titan ou algo do género.
Ainda segundo esse leak:
Two Unknown Nvidia GPU > 7552 Cuda cores (118 CUs) > 1.11GHz core clock > 24GB of memory GB5 Compute score: 184096 (Open CL) https://browser.geekbench.com/v5/compute/207559 > 6912 Cuda cores (108 CUs) > 1.01GHz core clock > 47GB of memory GB5 Compute score: 141654 (Open CL) https://browser.geekbench.com/v5/compute/287
"name": "OpenCL Device Driver Version",
"value": "445.01",
"name": "OpenCL Platform Version",
"value": "OpenCL 1.2 CUDA 11.0.0", {
"id": 75,
"name": "Clock Frequency",
"value": "1.20 GHz",
"ivalue": 1203,
"fvalue": 1203.0
}, "name": "OpenCL Platform Version",
"value": "OpenCL 1.2 CUDA 11.0.28",
"name": "OpenCL Device Driver Version",
"value": "445.35", {
"id": 75,
"name": "Clock Frequency",
"value": "1.20 GHz",
"ivalue": 1203,
"fvalue": 1203.0
},



{
"id": 3038,
"name": "CUDA Device L2 Cache Size",
"value": "33554432",
"ivalue": 33554432,
"fvalue": 33554432.0
},