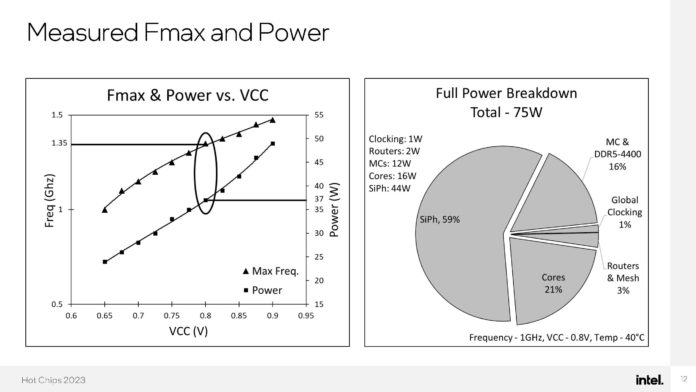
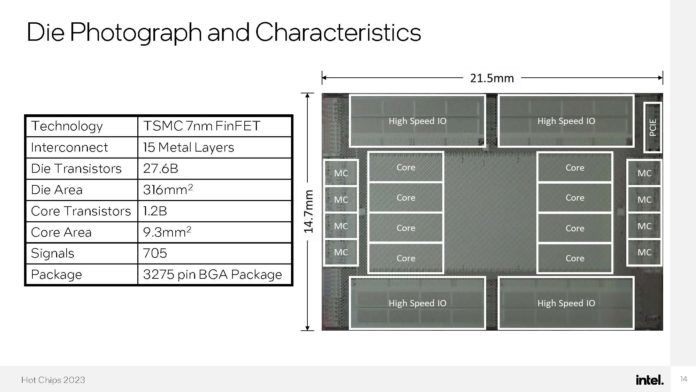
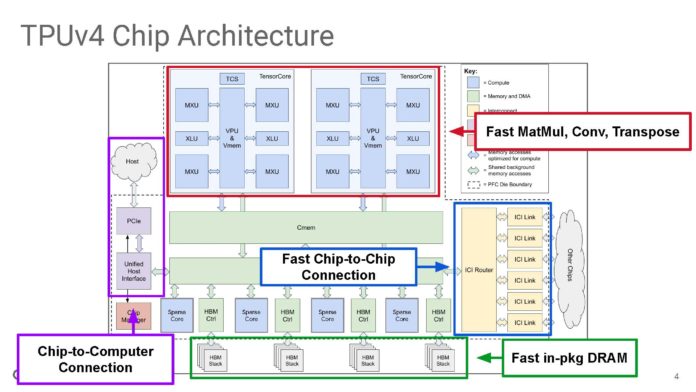
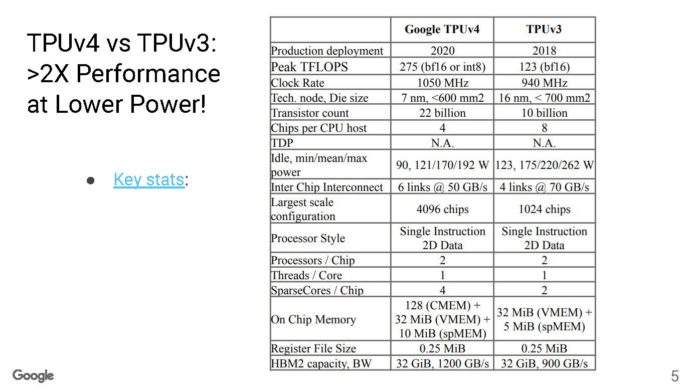
Nemesis11
Power Member
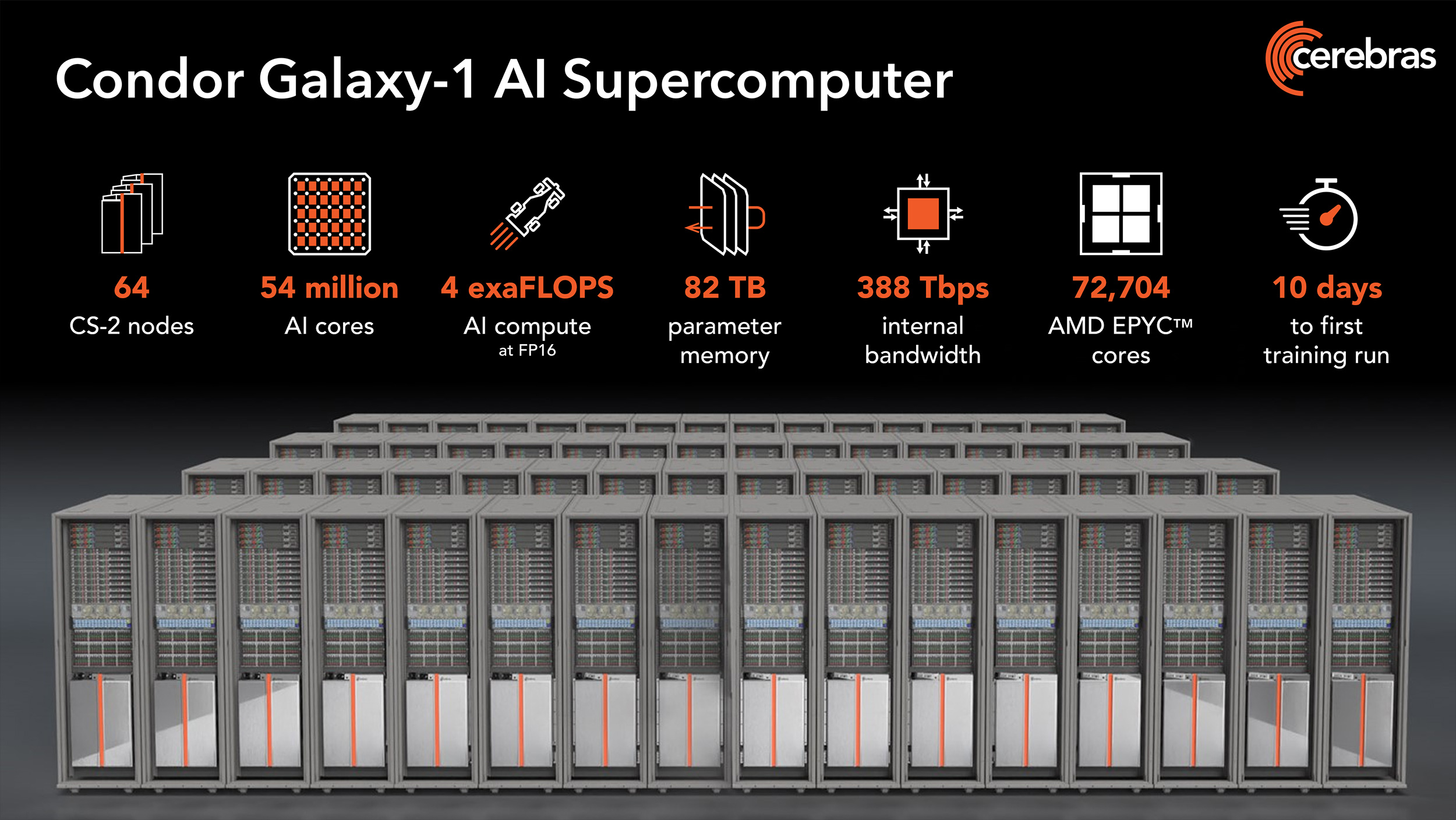
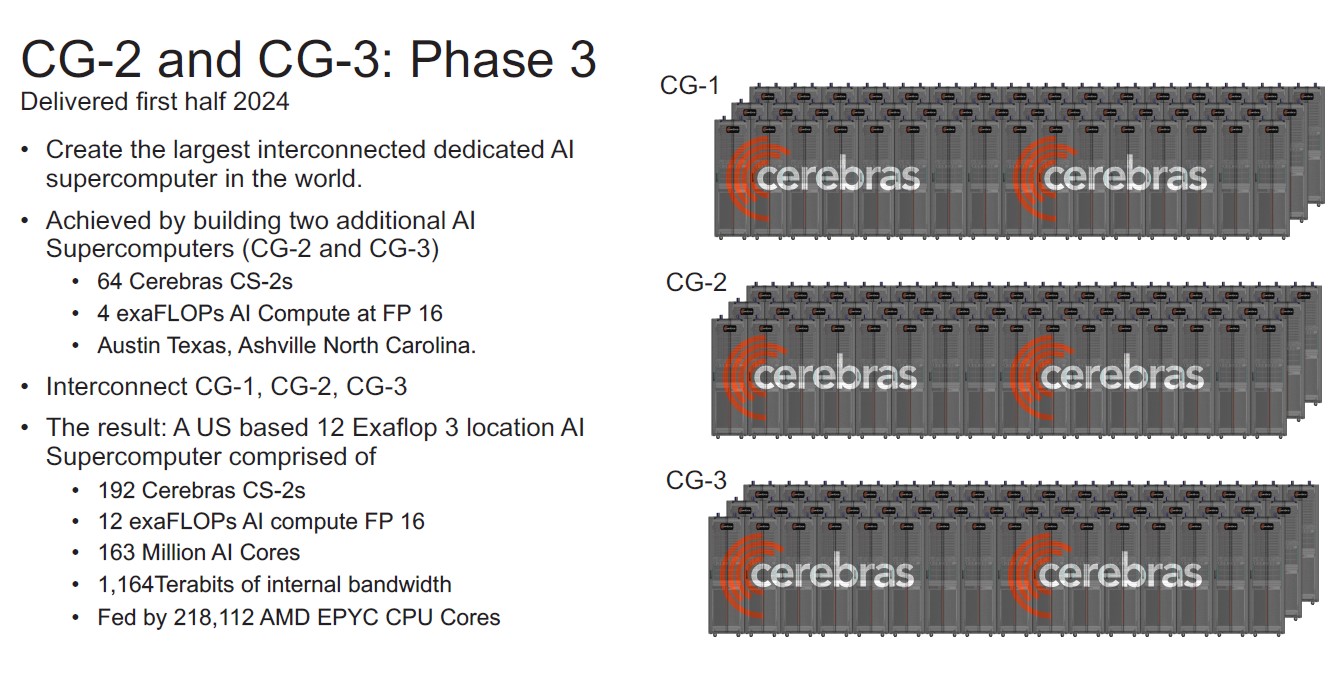
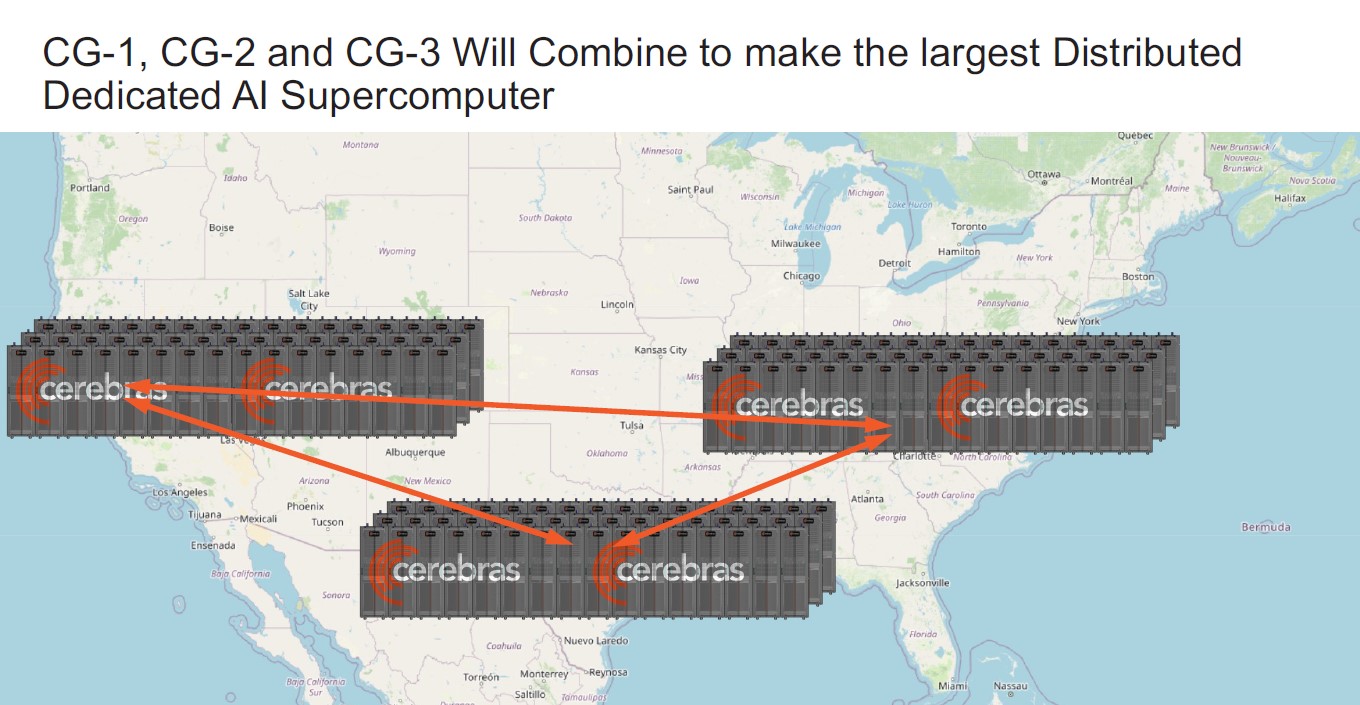
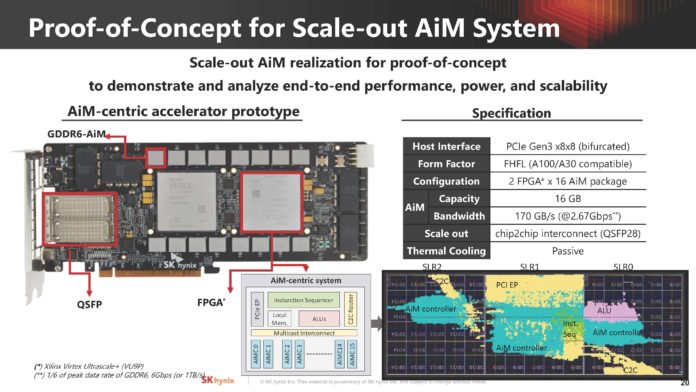
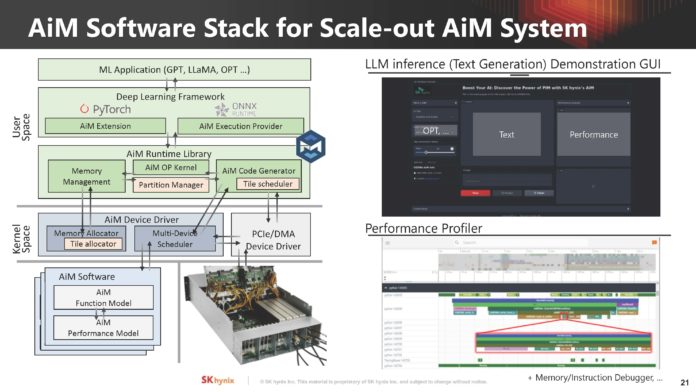
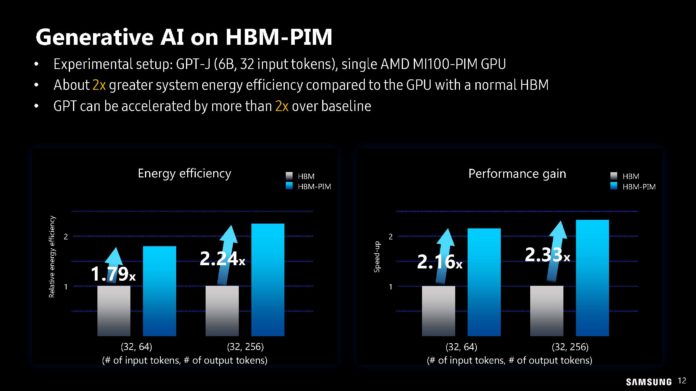
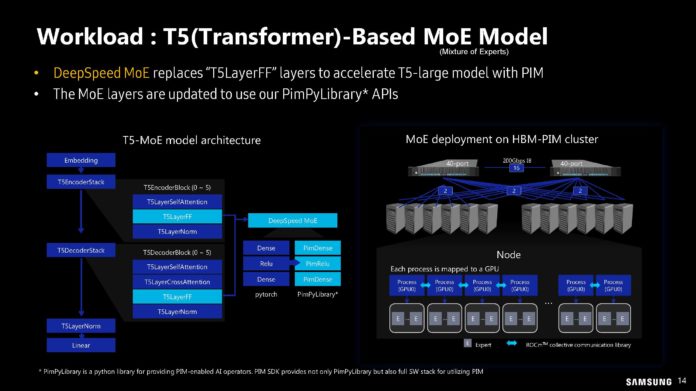
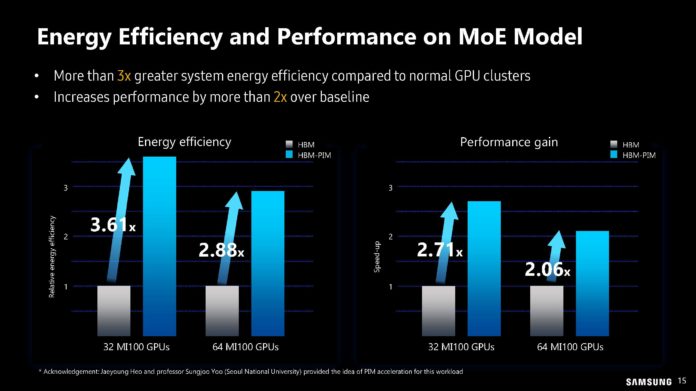
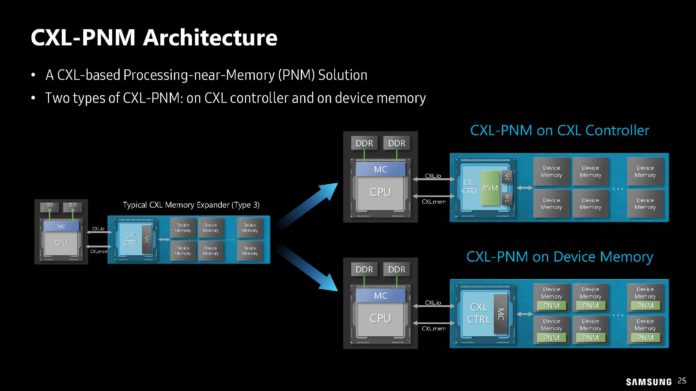
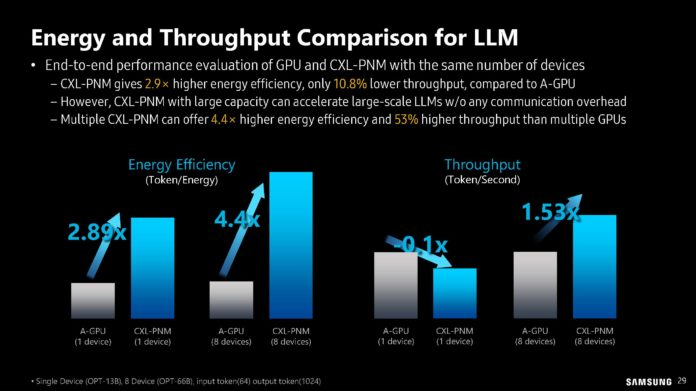
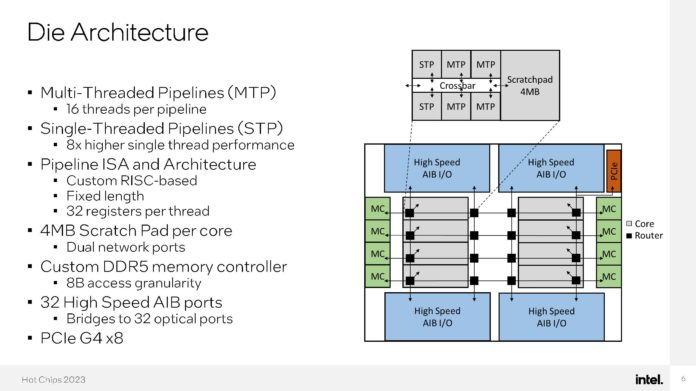
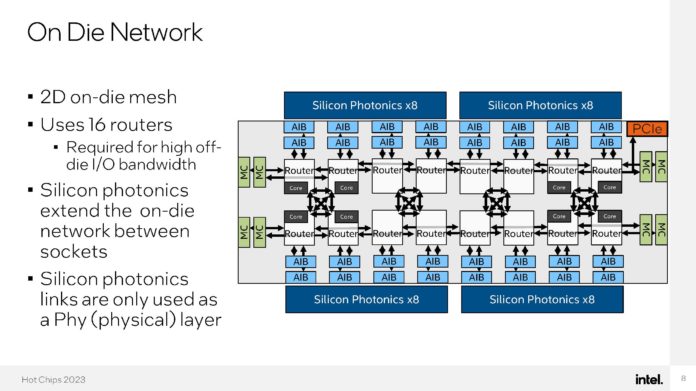
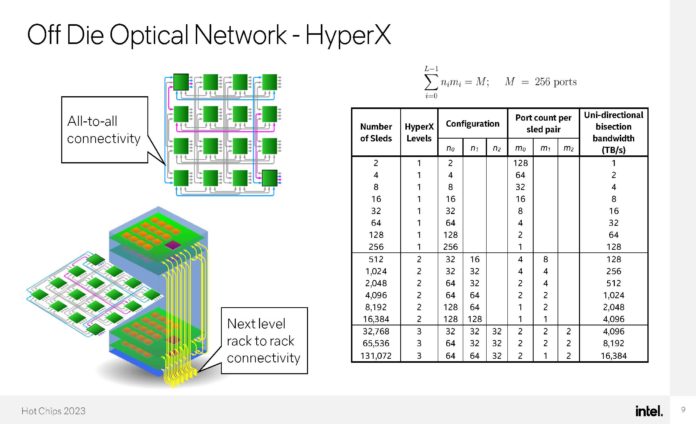
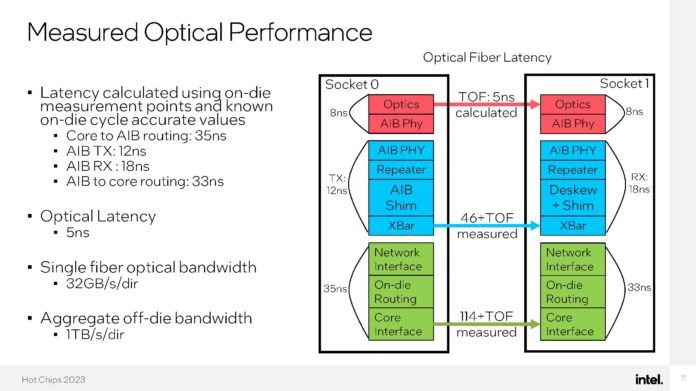
O DPU da AMD (Ex-Pensando), numa placa de rede Dual 100 Gbit. O SOC tem 16 Cores ARM A72, 32 MB de Cache, dual Channel DDR4 ou DDR5, 32 Lanes Pci-Ex Gen4 e capacidade para ser usado em placas Dual 200 Gbit. O mais importante, por ser um DPU, são os aceleradores a nível de rede e processamento.




https://www.servethehome.com/hands-...a-secret-lab-arm-nvidia-dell-vmware-esxi-upt/
Uma das coisas que acho interessante nestas placas, é que eles têm uma função bastante especifica, mas ao mesmo tempo, neste exemplo desta placa da AMD, têm múltiplos Cores genéricos ARM, 32 GB em DRAM para memória, 64 GB em NAND para storage e até uma FPGA. Corre Linux, como Sistema Operativo interno.
O uso é bastante especifico, o formato é uma placa Pci-Ex, mas na realidade, está ali um computador completo, genérico e bastante capaz.") Só falta colocarem um iGPU para se jogar Crysis.
Só falta colocarem um iGPU para se jogar Crysis. 
https://www.servethehome.com/hands-...a-secret-lab-arm-nvidia-dell-vmware-esxi-upt/
Uma das coisas que acho interessante nestas placas, é que eles têm uma função bastante especifica, mas ao mesmo tempo, neste exemplo desta placa da AMD, têm múltiplos Cores genéricos ARM, 32 GB em DRAM para memória, 64 GB em NAND para storage e até uma FPGA. Corre Linux, como Sistema Operativo interno.
O uso é bastante especifico, o formato é uma placa Pci-Ex, mas na realidade, está ali um computador completo, genérico e bastante capaz.
Só falta colocarem um iGPU para se jogar Crysis.