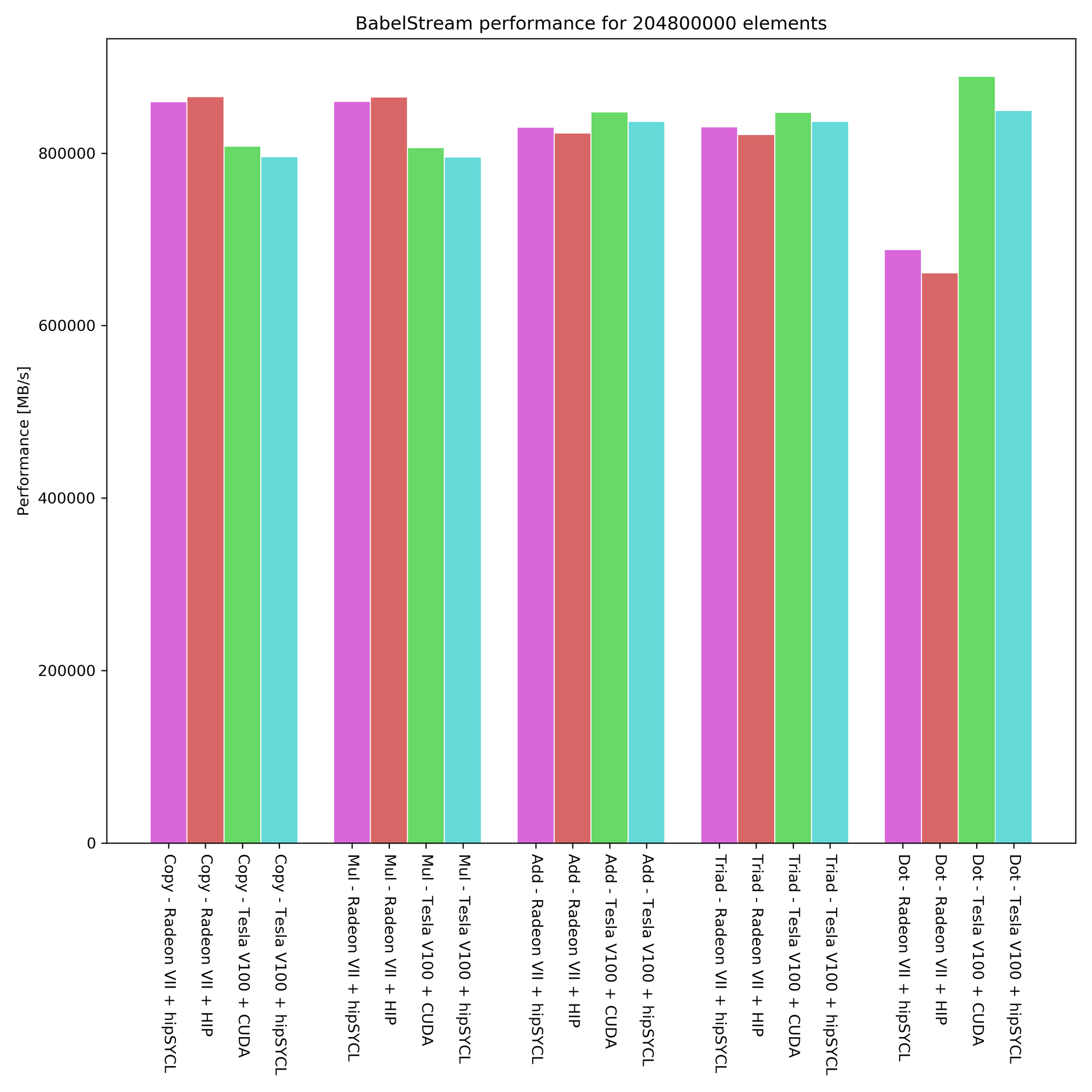
Como dizem os artigos acima, isto é algo feito para um determinado propósito, computação e cálculo científico.
Mas o que importa é o conceito em si
- 2015

- 2017 (post anterior de 2017)

http://www.computermachines.org/joe/publications/pdfs/hpca2017_exascale_apu.pdf
Já se sabe a abordagem da AMD com o ZEN e agora levada a outro nível com o ZEN (separação IO + CPU core), mas também se sabe que a AMD iria manter os die APU monolíticos, o que para muitos é estranho pois aquele layout faria supor que daria para um IO+CPU+GPU, e quem sabe o sonho de também incluir HBM.
Embora não tenha havido qualquer menção a APU, o que me fez pensar no mesmo foi esta imagem da apresentação

a menção à conexão CPU-GPU via IF leva-me a pensar precisamente que os die de GPU estarão num mesmo interposer (provavelmente activo à lá Vega) que o CPU e, lá está, que este também terá HBM (3 provavelmente), e que não será um tradicional sistema de discrete/dedicated CPU + GPU via PCIe.
Claro que a menção a custom CPU e GPU instruções (HW?) dedicado a HPC e AI, pelo menos parece confirmar que a nível de GPU a AMD pretende fazer divergir uma gama de GPU para esta área (linha Radeon Instinct), o que já tinha comentado no lançamento da VEGA 20.
A nível de software e como tenho dito neste tópico, o objectivo é tratar o CPU+GPU como algo único, o que seria mais fácil com um die monolítico, mas que como referi a AMD tem vindo a adicionar o suporte a dGPU, deduzo que eliminando o PCIe e sendo o link entre CPU e GPU o IF a tarefa seja mais fácil.
EDIT: Discrete GPU Code For AMDKFD, Radeon Compute Could Be Ready For Linux 4.17
Por último e não menos importante, a AMD não irá receber a totalidade dos 600M$, mas irá trabalhar directamente com a malta dos National Labs americanos e isso é importante do ponto de vista do software.
EDIT: nem a propósito, a AMD a lançar hoje um update ao ROCm
Radeon ROCm 2.4 Released With TensorFlow 2.0 Compatibility, Infinity Fabric Support
Mas o que importa é o conceito em si
- 2015
https://www.nextplatform.com/2015/07/30/future-systems-can-exascale-revive-amd/First, the Fast Forward concept stacks up memory close to the CPU-GPU hybrid compute to get the high bandwidth that applications require and cannot get with GPUs linked to CPUs over PCI-Express peripheral buses. The hybrid compute chip will have a single virtual address space, thanks to AMD’s Heterogeneous Systems Architecture (HAS) electronics, which by the way will be extended to work across discrete Opteron CPUs and AMD GPUs and is not limited to on-die setups.
- 2017 (post anterior de 2017)
http://www.computermachines.org/joe/publications/pdfs/hpca2017_exascale_apu.pdf
Já se sabe a abordagem da AMD com o ZEN e agora levada a outro nível com o ZEN (separação IO + CPU core), mas também se sabe que a AMD iria manter os die APU monolíticos, o que para muitos é estranho pois aquele layout faria supor que daria para um IO+CPU+GPU, e quem sabe o sonho de também incluir HBM.
Embora não tenha havido qualquer menção a APU, o que me fez pensar no mesmo foi esta imagem da apresentação
a menção à conexão CPU-GPU via IF leva-me a pensar precisamente que os die de GPU estarão num mesmo interposer (provavelmente activo à lá Vega) que o CPU e, lá está, que este também terá HBM (3 provavelmente), e que não será um tradicional sistema de discrete/dedicated CPU + GPU via PCIe.
Claro que a menção a custom CPU e GPU instruções (HW?) dedicado a HPC e AI, pelo menos parece confirmar que a nível de GPU a AMD pretende fazer divergir uma gama de GPU para esta área (linha Radeon Instinct), o que já tinha comentado no lançamento da VEGA 20.
A nível de software e como tenho dito neste tópico, o objectivo é tratar o CPU+GPU como algo único, o que seria mais fácil com um die monolítico, mas que como referi a AMD tem vindo a adicionar o suporte a dGPU, deduzo que eliminando o PCIe e sendo o link entre CPU e GPU o IF a tarefa seja mais fácil.
EDIT: Discrete GPU Code For AMDKFD, Radeon Compute Could Be Ready For Linux 4.17
Por último e não menos importante, a AMD não irá receber a totalidade dos 600M$, mas irá trabalhar directamente com a malta dos National Labs americanos e isso é importante do ponto de vista do software.
EDIT: nem a propósito, a AMD a lançar hoje um update ao ROCm
Radeon ROCm 2.4 Released With TensorFlow 2.0 Compatibility, Infinity Fabric Support
https://www.phoronix.com/scan.php?page=news_item&px=Radeon-ROCm-2.4-ReleasedEqually exciting is initial support for AMD Infinity Fabric Link for connecting Radeon Instinct MI50/MI60 boards via this Infinity Fabric interconnect technology. Infinity Fabric will become more important moving forward and great to see Radeon ROCm positioning the initial enablement code into this release.
Última edição:

")